









.jpg?width=1024&height=576&name=vRad-High-Quality-Patient-Care-1024x576%20(1).jpg)







%20(2).jpg?width=1008&height=755&name=Copy%20of%20Mega%20Nav%20Images%202025%20(1008%20x%20755%20px)%20(2).jpg)



 Keith Gardner
Keith Gardner
1 min read
Smarter Test Automation: The 4th Key to Unlocking a DevOps Culture
vRad’s philosophy around frequently deploying software updates relies heavily on test automation, which ensures adequate test coverage for each...

As a 24/7/365 radiology company, vRad’s technology is the backbone of everything we do. In order to deliver patient care, our client facilities must be able to communicate with our servers – and for us, that’s every day, every night, every weekend, every holiday… you get the picture.
In short, vRad systems must be highly available.
 |
Highly Available System: A system that can be accessed consistently with very little to no down-time. |
Today I’m going to discuss how we prepare for a disaster in order to minimize down-time and ensure the continuous delivery of services to our clients and the 5.9 million patients we serve each year.
In order to measure success and failure when it comes to server up-time, it’s important to have an up-time goal to measure against. For the uninitiated, calculating up-time is a simple equation:
Up-time = (total time – down-time) / total time
vRad does a large amount of emergency medicine. We handle cases where seconds and minutes matter. With regard to up-time, those seconds and minutes are precious.
Seconds and minutes with 99.95% up-time means:
We don’t have room for failure at vRad. If a car crash trauma case with a suspected intracranial hemorrhage comes to an ER we serve, we have to be ready to serve that patient, all day, every day. Those seconds matter to our patients and they matter to us.
At vRad, we target 100% up-time.
We monitor the stability of our platform using a metric we call nine(s) – the number of 9s of uptime we have (e.g., 99.99%). We use this information to decide how much change we allow in our platform.
As a leading radiology company, continually improving our systems and processes is part of our company’s DNA, and that means consistently enhancing our platform. Balancing the amount of change by gauging our nine(s) is part of that process. While we have many processes in place for ensuring high quality changes, making changes inherently introduces risk. When we approach an up-time of 99.95%, we become very selective about making changes to our platform and only allow the implementation of critical fixes. This reduces potential risk and allows our platform up-time numbers to stabilize.
Diligence and consistent tracking help us to maintain our up-time goal across all systems, which we monitor in our Technology Service Availability Report:
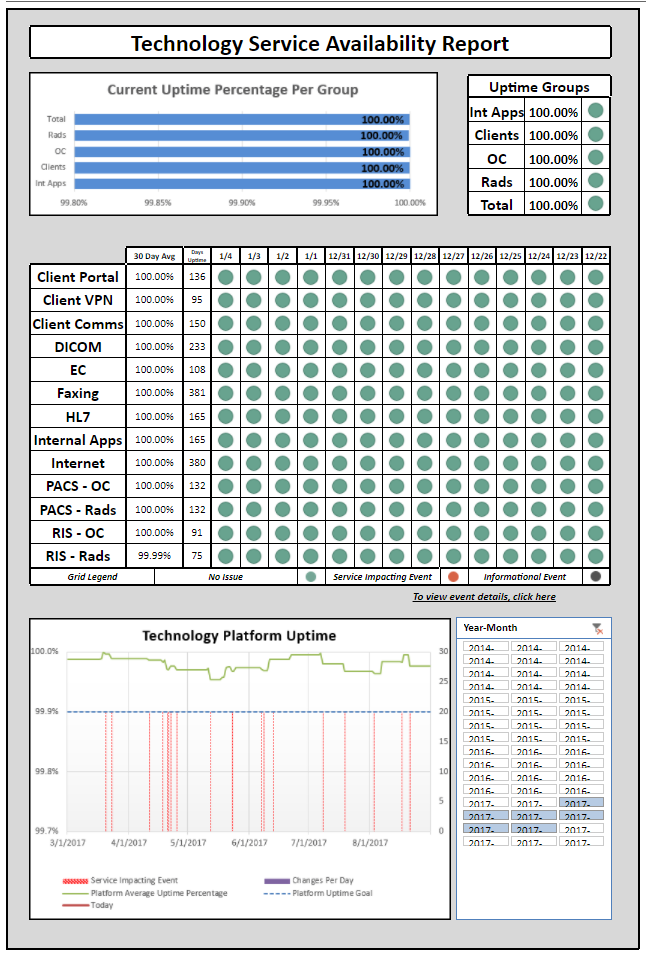
We also investigate any down-time events to garner a deep understanding of the root cause(s) and make corrections/adjustments based on our analysis.
Stringent development and maintenance practices go a long way toward making our up-time goal of 100% achievable – but at a certain point the biggest threat to up-time is an unexpected disaster taking out our primary data center.
A strong disaster response model is critical to gauging nine(s), as any data center related issues can cause major outages with little that can be done to protect your nine(s) if you haven’t prepared ahead of time.
We take outages very seriously. There are many different disaster recovery strategies including Cold Sites, Warm Sites, and Hot Sites – each of which provides differing costs and time to recovery.
At vRad, we use a Hot Site model to maximize our up-time. Let’s explore why that’s important.
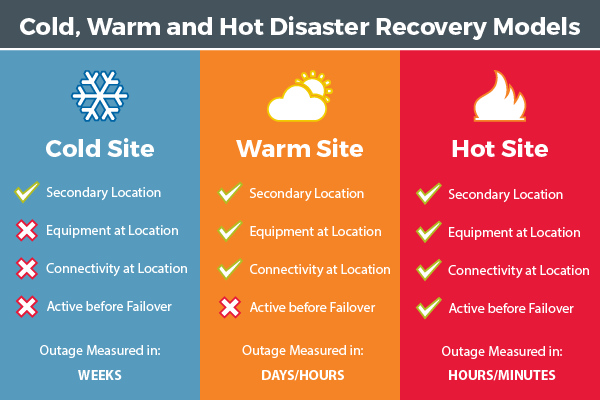
Cold Site strategies rely on a secondary datacenter location that is ready for equipment in the case of a disaster. The location is not connected to the internet beforehand and the equipment must be relocated and set up from scratch.
The Cold Site disaster recovery strategy is easily the cheapest to maintain but requires the longest potential outage duration, typically lasting weeks.
A Warm Site strategy consists of a datacenter pre-populated with equipment and connectivity. Yet, the backup equipment and software may be out of date and the datacenter would only ever become active in the case of a failover. Because a Warm Site datacenter is not in use until needed, you simply don’t know the status of the site – extra outage time is typically incurred as unforeseen issues arise during failover.
Failover to this type of data center still involves a significant outage duration, hours at best and most likely days, although shorter than a Cold Site Strategy.
The Hot Site strategy consists of having a duplicate datacenter configured to handle full production load and near real time synchronization of data. In the event of a failover, the production load will be re-directed to the Hot Site and disruption of service is minimal: hours, possibly minutes.
Even with Hot Sites, where outages are measured in hours, we architect the system differently as we cannot tolerate hours of outages. We further break down the Hot Site strategy into Active/Passive (outages measured hour(s)) or Active/Active (outages measured in minute(s)).
In an Active/Passive configuration, the systems in the disaster recovery datacenter are passive and will only receive load in the event of a failover. Because the systems are passive, functionality is not assured. Over time, software and hardware is updated and maintained, but typically are not tested under a production load. When the passive configuration is needed due to an outage event, unpleasant surprises can arise and increase your downtime.
vRad uses an Active/Active hot site configuration to maximize up-time. The systems in the disaster recovery datacenter are included as part of the day-to-day production load. The Network, Storage systems, Servers, Software … take a percentage of the production load at all times. This strategy ensures that that the disaster recovery datacenter is functional as these systems are part of production. We know our recovery center will work in a disaster simply because it already is!
I hope you enjoyed this high-level view of vRad’s disaster recovery model – and I hope you join me throughout the year as I dive deeper into how we maintain our servers here at vRad.
Back to Blog
1 min read
vRad’s philosophy around frequently deploying software updates relies heavily on test automation, which ensures adequate test coverage for each...
.png)
1 min read
For the latest information on vRad’s Artificial Intelligence program please visit vrad.com/radiology-services/radiology-ai/ Accelerating care delivery

1 min read
Today we have the capability—unparalleled in human history—to compile enormous amounts of information, then apply sophisticated analytic tools and...
vRad (Virtual Radiologic) is a national radiology practice combining clinical excellence with cutting-edge technology development. Each year, we bring exceptional radiology care to millions of patients and empower healthcare providers with technology-driven solutions.
Non-Clinical Inquiries (Total Free):
800.737.0610
Outside U.S.:
011.1.952.595.1111
3600 Minnesota Drive, Suite 800
Edina, MN 55435